Will data size be the problem for physical AI?
If we are using LLMs to train physical AI, anyway.
In this year alone, so many hot industry paradigm-defining keywords sprang to life in the AI space. The latest seems to be ‘Physical AI.’ Having a general-purpose AI that can control robots, interact with our phsyical environment without having a laboratory-like settings that do not have all sorts of things that can go wrong.
My understanding is that the discussion on whether LLMs based on transformer architecture is actually the ‘right’ model to create a true Physical AI is still ongoing. This post is not going to touch upon this, but rather a problem that is somewhat easier for me to grasp - data. Specifically, it’s about the absolutely bonkers amount of data these systems need just to learn basic physical tasks.
Starting with what I know (sort of)
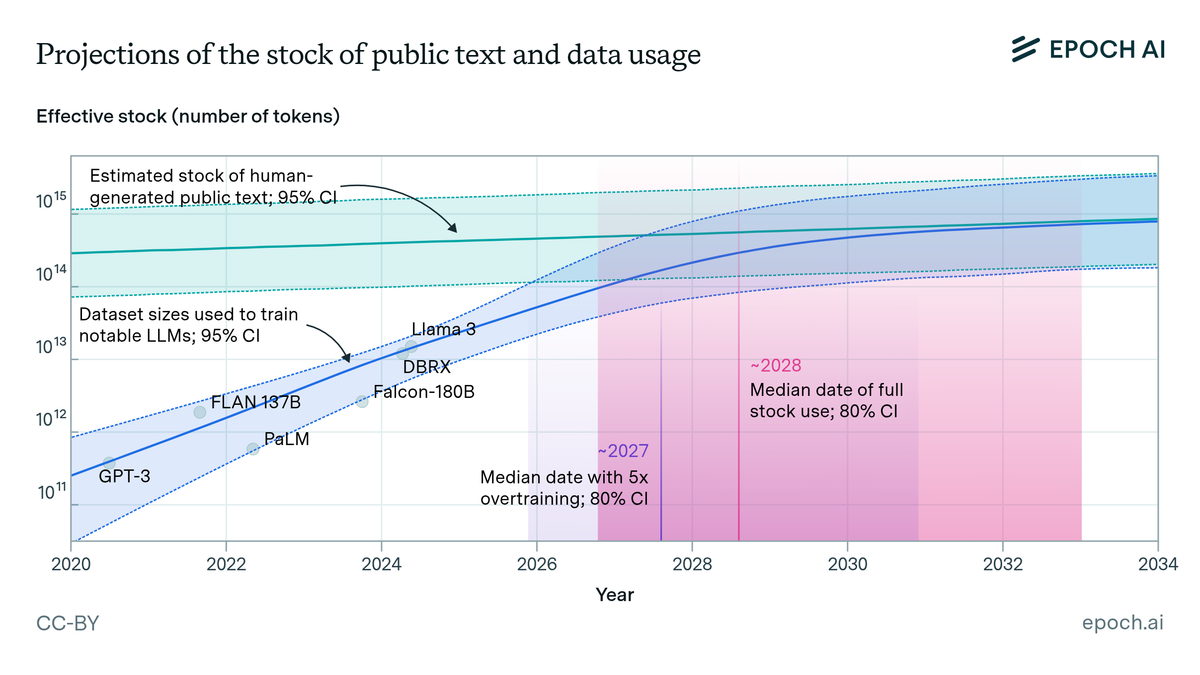
When OpenAI trained GPT-4, they used something like 13 trillion tokens—roughly 45 terabytes of text. The number itself didn’t seem significant to me until I saw that we are quickly using up the stock of human-generated text available.
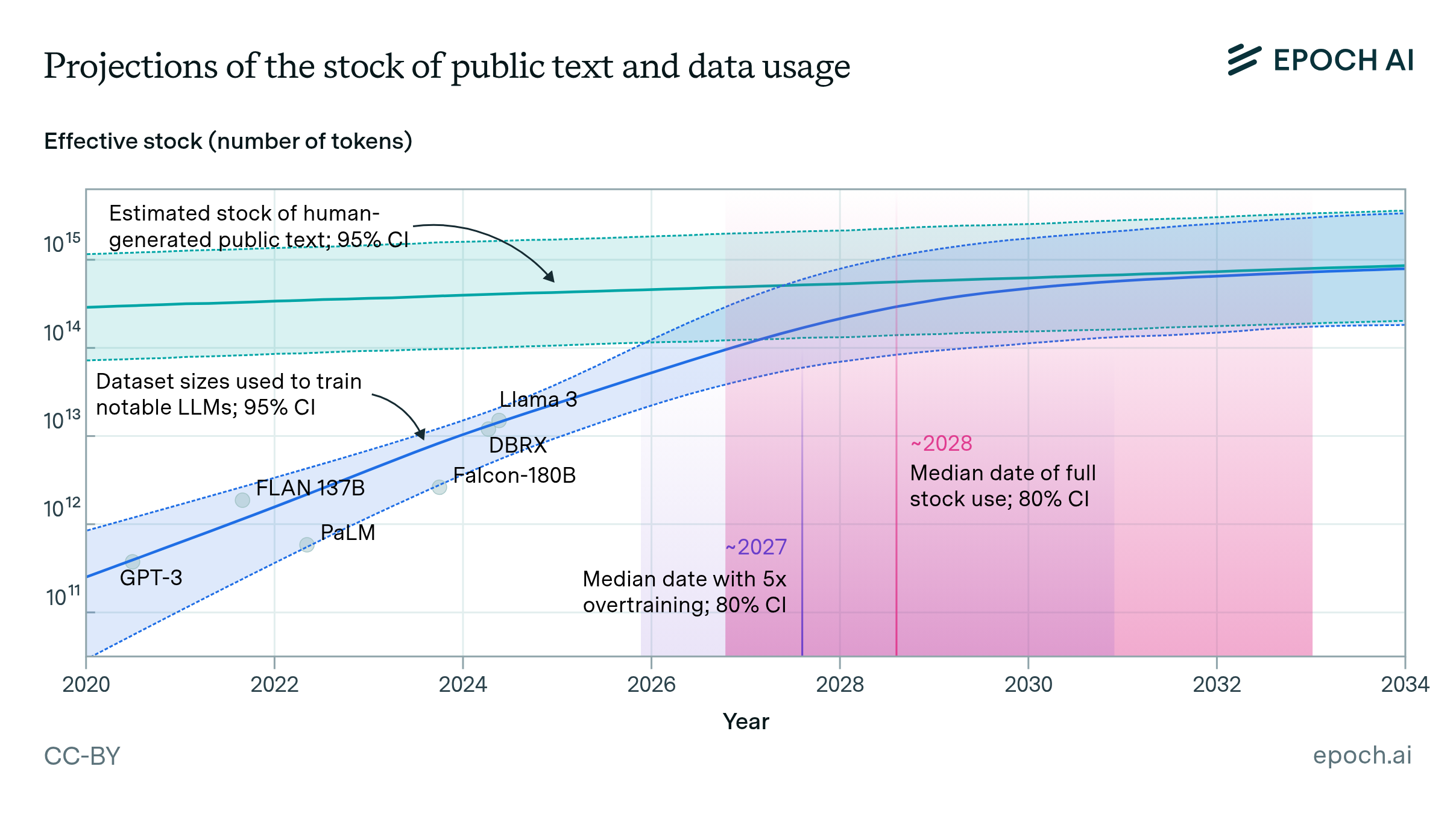
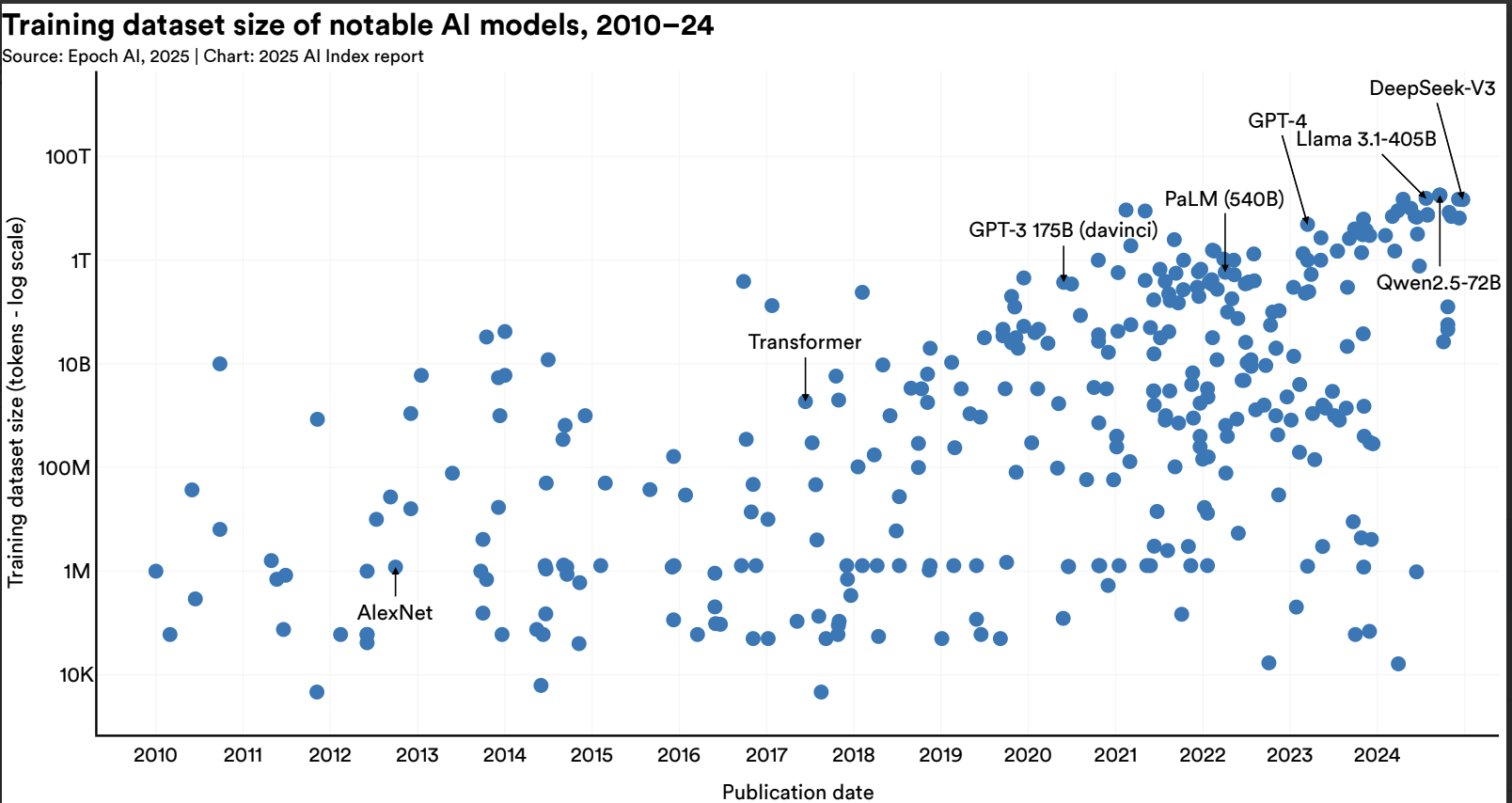
Dataset sizes have continued to increase quickly - the latest models seem to continue to need more and more data - EpochAI estimates training compute has increased 5x year-on-year for the frontier models.
And as the LLMs have evolved beyond text to multimodal, the amount of compute and data required to train them seemed to have increased quickly, according to study by Stanford and Epoch AI.
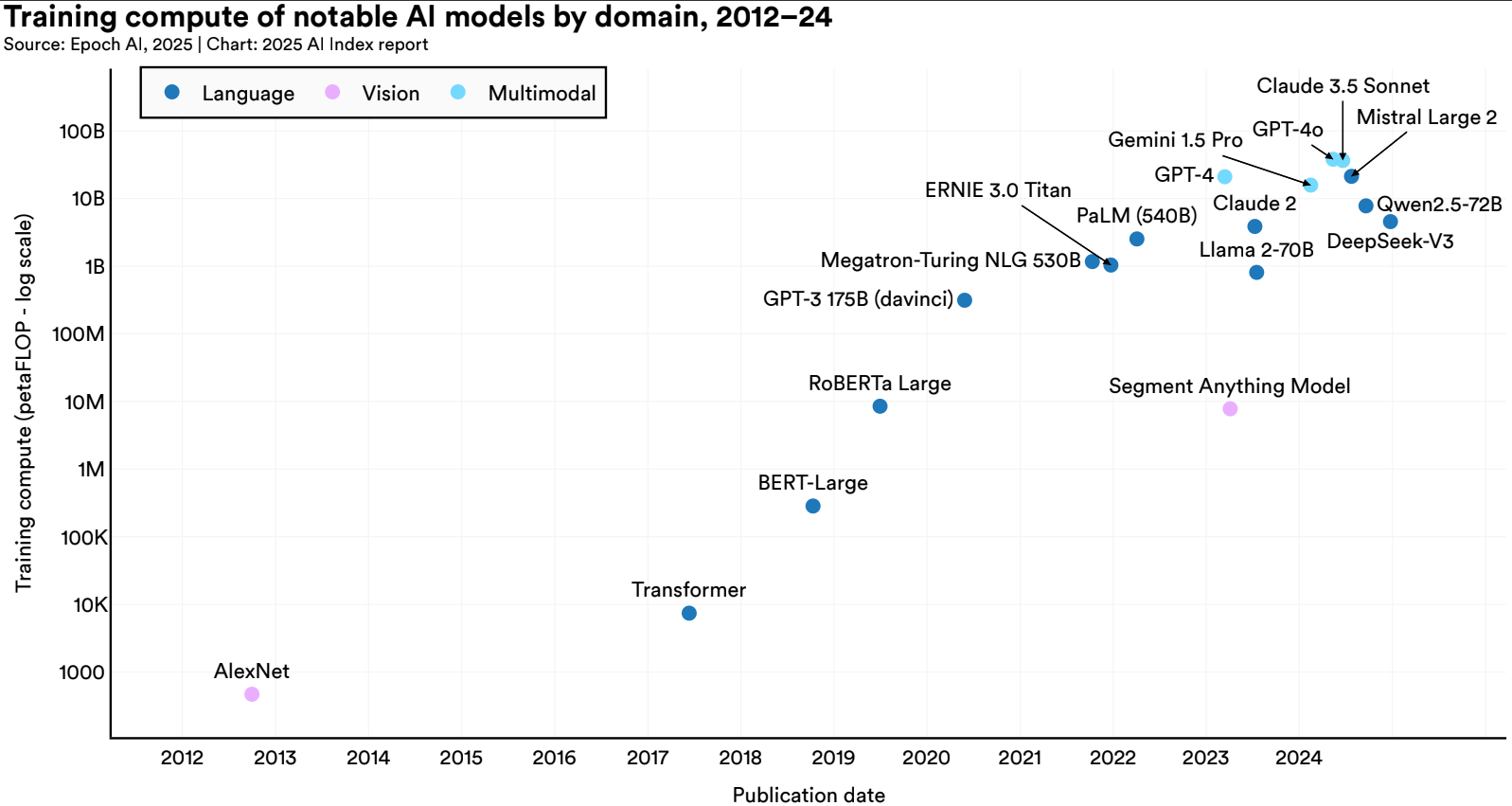
In fact, comparing the max training compute between language and multimodal models show that multimodal is 80% larger. Comparing the average training compute needed for frontier models released in 2024 between language and multimodal models show that the gap is over 3x.
Then what happens when the data needs to expand beyond 2D to a full 3D model-filled world? Are we going to see 3x difference between the multimodal models today and the Physical AI models of tomorrow? I think the data and compute required to just render the digital environment the Physical AI needs to train suggests that the jump in training compute and data will be significantly larger.
Digital twins: a perfect copy of reality
Nvidia’s recent keynote speeches (summarized by my colleague Jahachu) suggest that a fundamental part of training a physical AI will require a digital ‘dojo.’
This would probably require something like a video game rendering of a 3D space, but accurate within 1 millimeter. Nvidia’s own documentation and my own research shows that:
- A factory floor that’s about 182 square meters (roughly 2,000 square feet—a decent-sized apartment) requires 1GB of GPU memory just for the basic 3D structure
- The sensors collecting this data in places like Samsung’s semiconductor fabs? They’re generating 20 terabytes per second
- And this is before you add physics engines so the AI can understand how things actually move and interact
Those static 3D models are just the starting point. Physical AI doesn’t just need to know what a space looks like—it needs to understand how things change over time. A robot learning to pick up objects has to simulate thousands of scenarios: different weights, textures, grip angles, lighting conditions, surface friction.
In other words, one hour of robot behavior could require petabytes of data computed for training. That’s more than 1,500 times the entire GPT-4 training dataset.
I’m still not sure I fully believe this number, but multiple sources point to similar orders of magnitude.
The pattern I’m seeing: each AI generation needs exponentially more
Based on the past data point, each frontier AI model has continuously increased training dataset.
- Text-based AI: gigabytes to terabytes
- Image generation: terabytes
- Video understanding: petabytes
- Physical AI: probably hundreds of petabytes and beyond
What’s happening is that physical AI doesn’t just need one type of data—it needs everything at once:
- LiDAR point clouds (for understanding space)
- Photogrammetry (for textures and appearance)
- Sensor readings (audio, tactile feedback, temperature, pressure)
- Action sequences (showing how things behave)
- Temporal data (how everything changes moment to moment)
I’m guessing this multimodal requirement is what will create the explosion. It’s not 2x or 10x more data than previous AI generations. It’s potentially 100x or 1,000x more.
What this means for costs
Here’s what I found about training costs, and honestly, it’s concerning: the cost of training state-of-the-art AI models has been growing about 3.7 times per year. This estimate only includes the costs of energy, hardware acquisition and operation costs. If one includes the costs of collecting these real-world data (which do not yet exist in large volumes as it did for text and video data online), the costs of training & creating a physical AI probably becomes significantly larger.
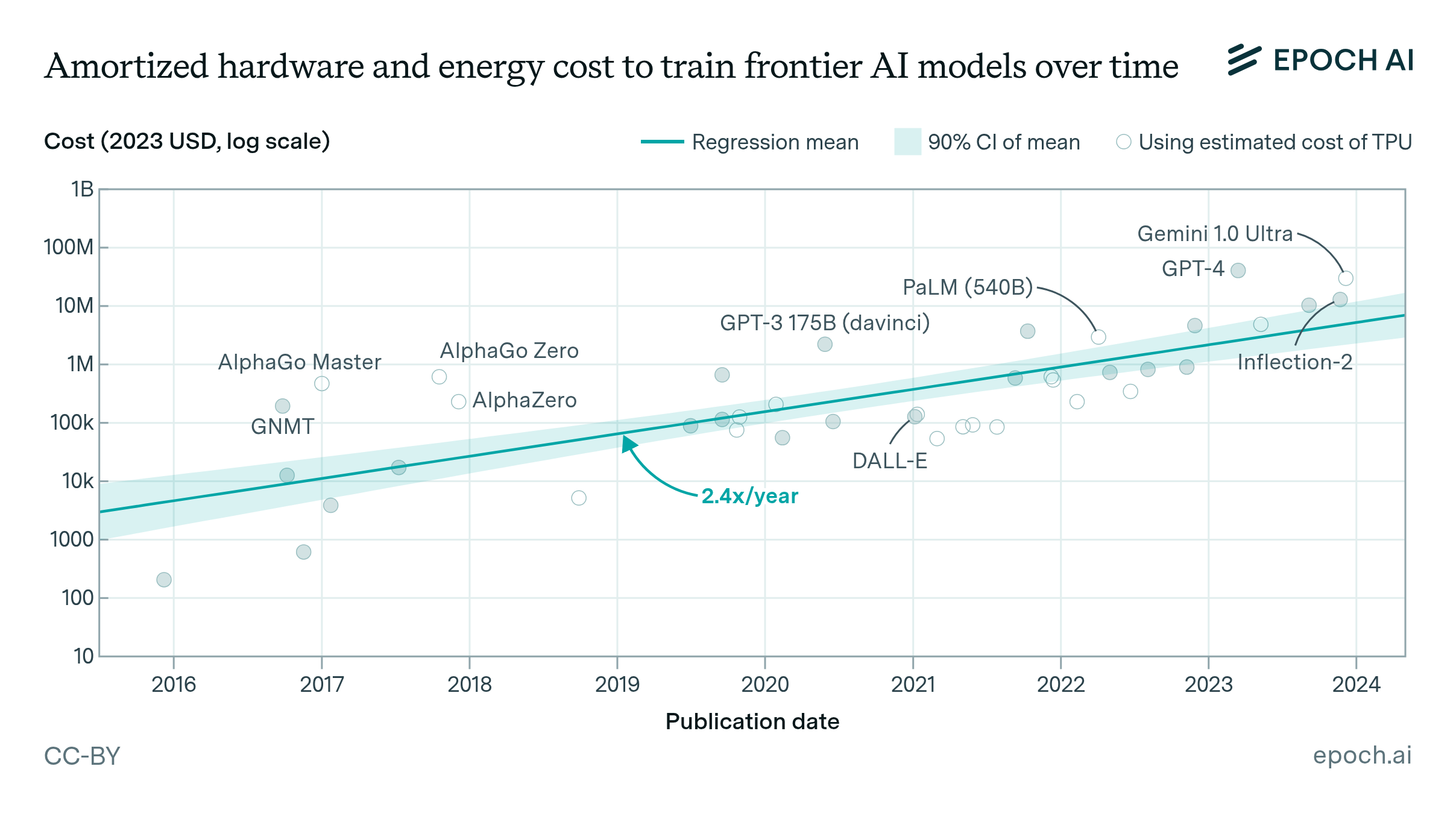
What that trajectory means:
- Today’s cutting-edge models: tens to hundreds of millions of dollars
- By 2027-2028: individual training runs could hit $1 billion
- Physical AI models, with vastly larger data needs: potentially much more
It is true that the increasing data and compute requirements to train a frontier model is being offset by:
- Hardware efficiency: GPU costs per FLOP keep dropping, and companies like NVIDIA and AMD keep pushing specialized AI chips forward
- Algorithm improvements: Better training techniques, smarter architectures, more efficient optimization
Yes, both of those help. However, the past data suggests that they alone have not yet offset the massive costs of training & running LLM models. Since AI has now become a thing of an arms race for both the businesses & and governments, the ballooning costs will not deter more R&D and investments unless it becomes financially not feasible to continue.
What I think this means
Given the continuously, exponentially increasing data and compute requirement, I think we may see a new layer of infrastructure for Physical AI. In the past, every major tech shift needs new infrastructure. The internet needed fiber optics. Cloud computing needed data centers. EVs need charging networks. What will be the new infrastructure layer for Physical AI?
If the size of data is the real limiting factor, here are some ideas:
- Compression algorithms that understand 3D structure, that can provide real-time compression & streaming
- Preprocessing that removes redundancy without losing information
- Data format optimization across different platforms
I’m seeing some signs of why these may become critical:
- NVIDIA’s Cosmos platform (launched January 2025) explicitly highlights efficient data representation
- Amazon runs 1 million+ warehouse robots, generating petabytes of training data daily
- Autonomous vehicle companies process sensor data from thousands of vehicles continuously
- Manufacturing facilities or specialized industries such as healthcare will require highly accurate and constantly updating digital twins
But of course, this is all based on the assumption that current trends will continue to hold true.