커머디티가 되어가는 AI, 앞으로는 검증과 통합이 핵심(?)
AI의 비용은 분기마다 낮아지고 성능이 계속 개선되는 와중, 병목이 모델의 품질에서 메모리와 평가로 조용히 이동한다면 어떤 일이 벌어질까? 그리고 그 변화 속에서 실제로 가치를 가져가는 주체는 누구일까?
*이 글은 영문으로 2026년 1월 23일에 먼저 발행되었습니다.
현재 대중의 내러티브는 여전히 "더 큰 모델=더 좋은 성능"이라는 프레임에 갇혀 있는듯 하다. 어느 정도는 맞는 말이지만, 내가 느끼기에는 조금 다르다. AI 모델의 기능 자체는 점차 커머디티화(Commoditization, 범용화)되고 있으며, 이 능력을 실제 업무에 활용될 수 있도록 안정적이고 저렴하게 구현해내는 시스템과 노하우로 가치가 이동하는 것으로 보인다.
SUMMARY
- 메모리가 진짜 병목: 컨텍스트 윈도우(context window)가 아무리 커져도, 장기적인 기억력이나 복잡한 작업에서의 신뢰성을 보장해주지는 않는다.
- 엔지니어의 검증 비용 증가: 멀티 에이전트 워크플로우, RAG, 컨텍스트 엔지니어링은 성능을 높여주지만, 그만큼 비용과 실패 가능성을 높인다.
- 결국 사람이 진짜 병목: AI의 출력 속도는 빨라져도, 이를 검증(Evaluation)하는 인간의 속도는 그대로다.
- 초기 승자는 서비스 레이어: 특정 도메인에 특화된 엔지니어나 컨설턴트들이 프롬프팅과 최적화 등을 통해 가치를 만들어내고 있으나 – 이런 서비스들은 굉장히 특화되어 있어 일반화하기 어렵다.
- 비확정적인 AI 아웃풋, 플랫폼화는 어려워: 기존 SaaS 서비스에 대한 확정적 기대치는 AI의 비확정적(non-deterministic) 결과물과 괴리가 크다. 따라서 아웃품이 깔끔한 플랫폼 보다는 '인프라'와 '서비스' 모델이 치고 나갈 것 같다.
- 락인을 하려는 자와 피하려는자: 프론티어 모델 제공업체들이 사용자들을 자사의 UI와 모델 스텍에 락인되도록 경쟁하는 가운데, 사용자들은 락인을 회피하기 위해 다양한 시도가 진행중이다.
1.핵심 제약: 메모리가 진짜 병목
LLM의 컨텍스트 윈도우는 단기 기억이라는 것은 다들 잘 아실것이다. 이게 가득 차면 이전 데이터는 누락되거나 압축되는데, 이는. 긴 대화를 하다 보면 앞 내용을 자꾸 까먹는 동료와 일하는 것과 동일하다. 컨텍스트 윈도우를 늘리는 소프트웨어와 하드웨어(메모리!) 기술은 놀랍지만, 그것이 곧 지능의 일관성이나 신뢰성으로 직결되지는 않는다.
AI 시스템을 사무실로 생각해보면:
- 컨텍스트 윈도우는 책상과 같다. 공간이 좁으면 계속 치워야 한다.
- RAG(검색 증강 생성)는 구석에 있는 '책장'이다. 도움이 되지만 찾아오는 데 시간이 걸리고, 결국 서류와 책을를 작업대 위에 올려두어야 하므로 작업 공간을 차지한다.
- 진정한 장기 메모리는 '도서관'이다. 엄청난 양을 저장하면서도 필요한 것을 정확히 라벨링하고 다시 제자리에 갖다 놓는 정교한 시스템. 하지만 찾고 다시 읽어서 기억을 일깨우는 것은 시간이 걸린다.
결국 지금 우리가 하는 컨텍스트 엔지니어링은 기억을 큐레이션하는 기술으로 봐야 한다. 모델 자체에 장기 기억이 없기에, 인간이 억지로 메모리 시스템을 만들어 붙이고 있는 셈이다.
2. 엔지니어링 대응: 분산 워크플로우, 높아진 비용
가장 흔한 해결책은 작업을 여러 에이전트에게 나누는 것이라 할 수 있다. 오케스트레이터(지휘자)가 방향을 잡고, 하위 에이전트들이 특정 업무를 처리하며, 리뷰어가 최종 확인을 하는 식. 똑똑한 방식이지만 비싸다는 게 흠이다. 한 번의 호출로 끝날 일을 여러 번의 호출과 조정 비용(Coordination overhead)을 들여 해결해야 하기 때문. 그리고 이를 구현하는데 드는 개발비용은 범위에 따라 다르겠지만 상당히 크다.
RAG나 요약 레이어도 마찬가지다. '기억'은 돕지만 '판단'을 고쳐주지는 못한다. 문서를 잘 찾아와도 모델이 헛소리(환각)를 할 가능성은 여전하다. 결국 운영자 입장에서는 수많은 가드레일과 프롬프트 변수를 끊임없이 관리해야 하며, 이는 AI 활용이 여전히 '민주화'되지 못하고 기술적 상위 계층의 전유물로 남아 있는 이유가 된다.
3. ROI의 현실: 거품과 실질적 수익 사이
AI 도입과 지출은 분명 증가하고 있다고 본다. 그러나 투자 대비 효과는 고르게 나타나지 않는다. 공개 데모는 실제 워크플로우를 가리는 경우가 많다고 판단한다. 프롬프트 라이브러리, 예외 처리 정책, 인간 검토 과정은 잘 드러나지 않는다. 이로 인해 복잡한 장기 작업에서 AI가 "Plug-and-play"가 가능한지에 대한 기대가 과대평가된다고 생각한다.
실제 병목은 모델의 지능이 아니라 검증(Evaluation)이라고 판단한다. 코드가 아닌 작업에 대해 널리 합의된 신뢰 가능한 검증 프레임워크는 아직 부족하다고 본다. 이 상태에서는 전체 조직 단위로 워크플로우를 확장하는 것이 퀄리티 관리 측면에서 매우 어렵다고 생각한다.
비관적으로 보면 생산성 향상은 소수 전문가의 영역에 국한될 가능성이 있다고 본다. 반대로 낙관적으로 보면, 현재는 신형 플랫폼 기술이 표준화되기 전의 전형적인 초기 단계일 수도 있다고 생각한다. 어느 쪽이 맞는지는 아직 단정하기 어렵다고 판단한다.
4. 산업 역학: 돈은 어디로 흐르는가?
인프라 제공자와 도메인 특화 서비스들이 현재 수혜를 받고 있는 것은 명확하다. 최종 사용자에게 모델이 무엇인지는 중요하지 않다. 내 서비스가 빠른지, 정확한지, 더 오래 기억하고 더 오래 일할 수 있는지가 중요하다. 인프라 분야에서는 연산, 스토리지 그리고 오케스트레이션 레이어가 Value Capture를 하고 있다. 메모리가 병목인 현재 시점에서는 메모리와 연산력을 제공하는 업체들이 가격 협상력이 높다.
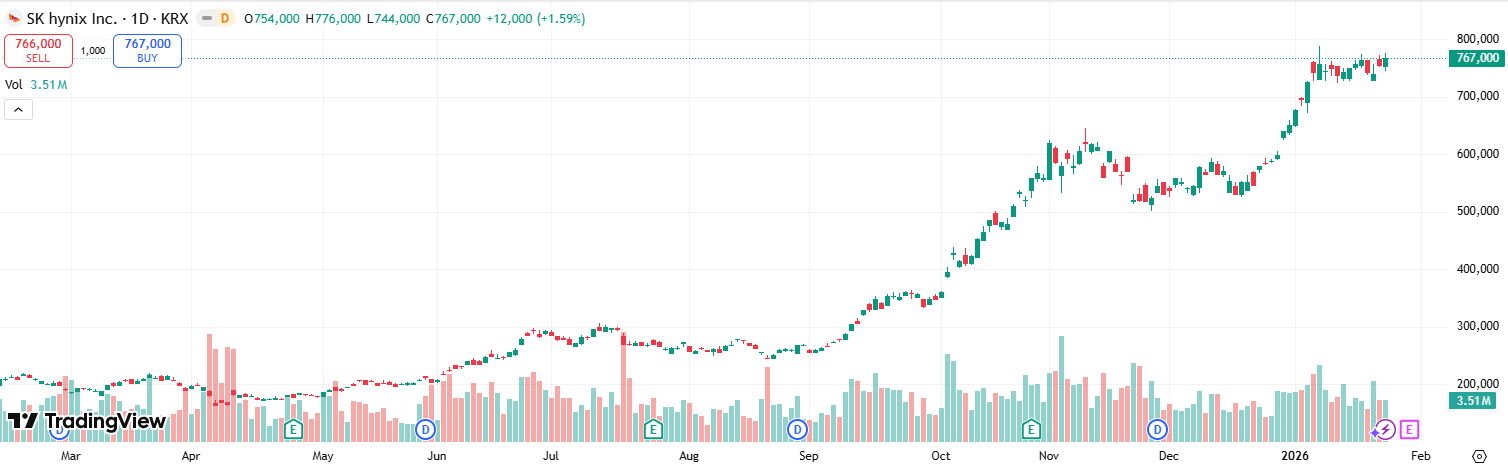
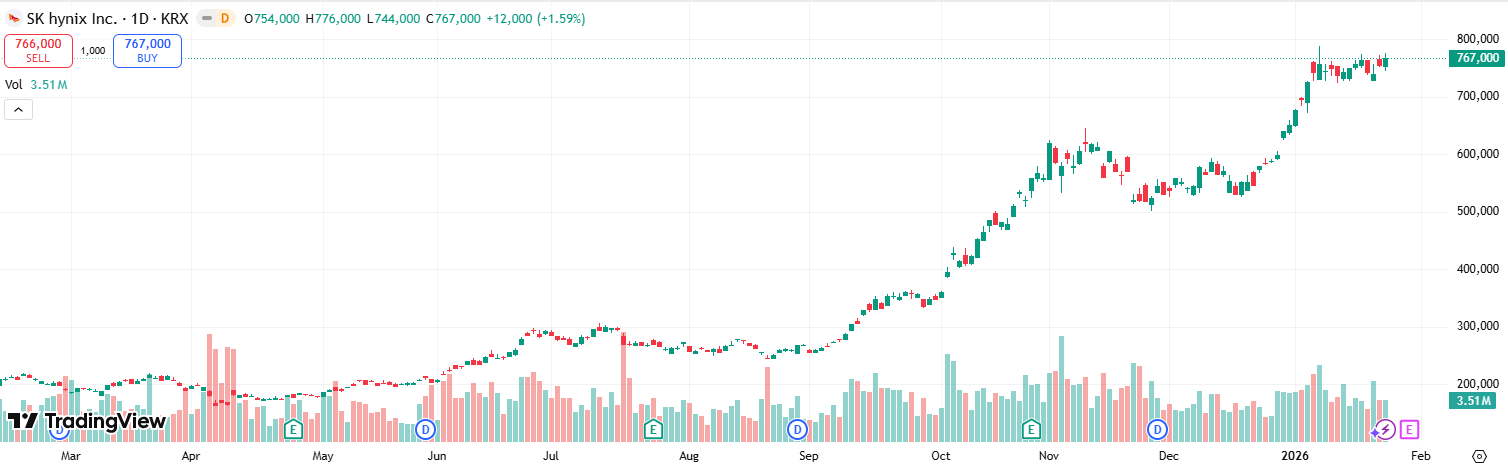
최근 몇 달간의 뉴스는 이를 뒷받침한다고 생각한다. 실제로 주요 메모리 제조사는 가격을 계속 큰 폭으로 (50%) 인상하고 있다. 고대역폭 메모리 분야의 선두 기업인 SK하이닉스의 주가 상승과, 메모리 생산 능력이 수요를 따라가지 못하고 있다는 반복적인 보도가 이를 증명해준다.
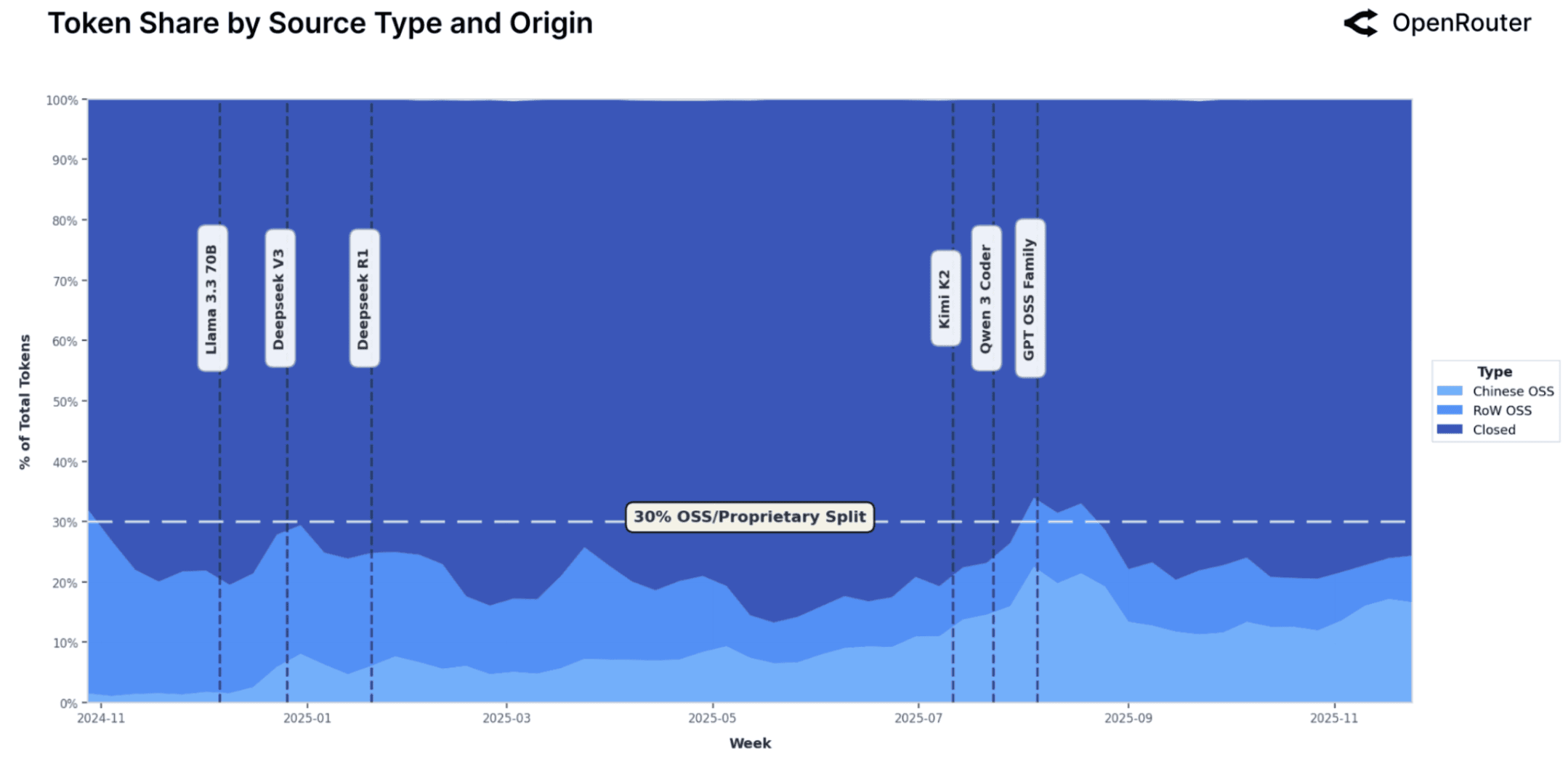
흥미로운 점은 오픈 소스 모델의 약진이라고 할 수 있다. 실제로 여러 AI 모델에 쉽게 연결하는 서비스 오픈라우터의 조사결과를 보면, 작년 기준 오픈소스 모델들이 약 30%정도까지 사용률이 올라왔다. 이런 트렌드는 필자가 접한 몇 곳의 B2C 컨슈머 앱 스타트업 사례들이 이를 잘 보여준다. 비용 때문에 최상위 폐쇄형 모델에서 오픈 소스 모델로 갈아탄 후, 파인튜닝과 프로세스 최적화에 집중한 결과 토큰비용을 낮춰 유닛 이코노믹스를 양수로 전환하면서도 유저의 리텐션은 그대로 유지해냈다. 이런 '최적화 노하우'가 지금 시장에서 가장 귀한 자산이고, 아직 시장에 보급되어 있지 않다고 본다.
이하는 필자가 생각하는 AI 서비스 레이어어 구조이다.
┌──────────────────────────────────────────────┐
│ User Interfaces / Workflows │
└──────────────────────────────────────────────┘
▲
│
┌──────────────────────────────────────────────┐
│ Domain-Specific Services (operators) │
│ - prompt tuning │
│ - model routing / cost-perf optimization │
│ - evaluation design & monitoring │
└──────────────────────────────────────────────┘
▲
│
┌──────────────────────────────────────────────┐
│ Middleware / Orchestration │
│ (agents, RAG, memory layers) │
└──────────────────────────────────────────────┘
▲
│
┌──────────────────────────────────────────────┐
│ Frontier Models / Foundation Models │
└──────────────────────────────────────────────┘
▲
│
┌──────────────────────────────────────────────┐
│ Infrastructure (compute, │
│ memory, storage, energy) │
└──────────────────────────────────────────────┘
훌륭한 서비스를 만드는 팀은 아마 이런 인프라와 AI 모델을 잘 배합해서 쓰는 숙련된 운영자의 모습을 띌 것으로 본다. 특히 아래 3가지를 갖출 것 같다.
- 프롬프트 튜닝을 통한 결과물의 일관성 달성
- 모델 라우팅과 비용/성능 최적화, 이를 달성하기 위한 다양한 모델 활용능력
- 검증(Evaluation) 설계력 - 평가 지표, 정확도 등 "좋은" AI 서비스에 대한 자체 검증/평가 기준
이는 소프트웨어 자체보다는 고도의 분석과 판단의 결합이다. 이런 팀들은 이미 있는 모델을 기반으로 필요한 기능을 빠르게 만들어낼 것으로 보인다. 다만 이러한 서비스는 빠르지만, 매우 특정한 문제에 최적화되지 않을까? 법무팀을 위해 설계된 워크플로우와 AI 산출물의 튜닝은 구매 팀으로 그대로 이전되기 어렵다고 생각하는 것은 큰 비약은 아니라 본다. 따라서 이런 서비스의 성장은 과거의 SaaS보다는 더 효율화된 전문가 집단의 SI/컨설팅 서비스 모델에 가깝다고 판단한다.
물론 팔란티어를 반례로 들 수 있다. 깊은 도메인 통합과 장기 계약, 강력한 플랫폼을 기반으로 엄청난 성장을 이뤄냈다는 것은 부정할 수 없다. 하지만 팔란티어 모델을 차용하고자 하는 스타트업들이 주창하는 “OO분야의 팔란티어”(Palantir for OO) 라기보다는 “X를 위한 롯데정보통신”(SI업체)에 가깝다고 느껴진다. 방어력은 높지만, 셀프서비스형 수평 플랫폼과는 거리가 있다고 본다. 실제로 미국에 상장되어 있는 Accenture(IT consulting, SI업체) 주가를 보면 장기적으로 이런 스타트업들의 절망편을 볼 수 있다.
5. 플랫폼 vs 서비스: 흔들리는 기존 SaaS의 문법
SaaS의 핵심 전제는 반복 가능성과 예측 가능성이라고 생각한다. 그러나 AI의 비확정성(non-deterministic)은 이러한 전제를 깨버린다. 같은 질문이 시간에 따라 다른 품질의 답을 낼 수 있다는 점은 결국 인간의 개입과 맞춤형 워크플로우를 요구한다.
미들웨어와 라우팅 레이어들이 시간과 특정 모델 의존성을 줄이기는 하지만 핵심 병못인 메모리와 검증문제를 해결해주지는 못한다. 이들은 배관이지, 기초는 아니기 때문이다. 그리고 이에 대항하여 주요 모델 제공자들은 개별 사용 케이스에 맞춰 UI와 스택 차원에서 락인을 강화하고 있다. Claude가 opencode.ai와 같은 프로젝트에 대해 OAuth접근을 제한한 최근 사례는 사용자 경험을 장악하기 위한 경쟁이 격렬하게 벌어지고 있음을 반증한다.
또한, 사용자들이 락인을 피하는 노력은 끝나지 않을 것이다. 회사 전체가 OpenAI의 서비스를 다양한 UI를 통해서 쓰면 회사가 종속될 수 밖에 없기 때문이다. 그래서 오늘날 오픈라우터같은 라우팅 레이어, 오픈 웨이트 모델, 자체 인터페이스는 이러한 움직임의 결과인 것 같다.
이는
6. 앞으로의 예상
단-중-장기적으로 보았을 때:
단기 (1-3 년). 인프라와 버티컬 서비스가 우위인 시장이 전개된다. 멀티-에이전트 시스템과 인간의 검증/통제가 보편화 된다. 이 때는 앞서 언급한 '서비스'가 더 강세를 보인다.
중기 (3-6 년). 더 안정적인 장기 메모리 아키텍쳐와 AI 평가를 위한 도구가 출현한다면, 반복 가능성을 보유한 플랫폼으로 중심축이 이동한다. 이들이 얼마나 더 커질지는 이 플랫폼들이 제공하는 기능이 표준화에 가까울지, 맞춤형에 가까울지에 따라서 다를것 같다.
장기 (6+ 년). 메모리와 검증이가 현재 상용 소프트웨어 수준의 안정성과 정확도를 달성한다면 수평적 플랫폼이 대세로 떠오른다. AI가 모델 뿐만아니라 워크플로우 레벨에서도 커머디티가 된다.
그렇다면 앞으로 뭘 지켜봐야하나?
현재 잠정 가설은: 현재의 AI는 '능력'을 범용화 하였지만, 메모리와 검증는 훨씬 느리게 범용화된다. 이런 병목은 스택 하단으로 이동하고 있다. 모델 품질이 병목인 시기에서 메모리, 오케스트레이션, 인간 판단으로 옮겨가고 있다.
위 가설이 현실화되는 것을 보기 위해 이하 현상들이 나타날지 지켜보고자 한다.
- 단순히 더 큰 컨텍스트 윈도우가 아니라 진정한 의미에서의 장기 기억을 구현하는 아키텍쳐 (또는 관련 논문)
- 코딩 외 작업에도 적용가능하며, 보편화되고, 신뢰 가능한 검증 프레임워크
- 정확도가 중요한 영역에서 인간 감독 없이도 반복 가능한 워크플로우가 가능해진다는 증거
이 조건들이 충족된다면 플랫폼이 대세로 떠오를 수 있다고 본다. 그 전까지는, 복잡하고 지저분한 워크플로우를 실제로 작동하게 만드는 인프라와 서비스에 가치가 집중 될 가능성이 높다고 생각한다.